
The AWS Summit in Paris last June was the occasion for Devoteam to discover how European companies see the Public Cloud as their new primary applicative environment, what type of workloads they prefer to move in the Cloud and which ones they prefer to keep on-premise.
We were particularly intrigued by the use case of AWS for Big Data technologies and followed two very developed presentations on this topic, the first one was related to Cloud-reach experience to set-up this type of infrastructure. The second interview co-presented by Abderrhamane Belarfaoui, CDO of Euronext, and Paul de Monchy Senior Consultant at AWS, spotlighted how the company successfully leveraged AWS services to renew their Big Data and DataLake platform and improve their quality of service.
Cloudreach is an exclusively public Cloud-oriented company created in the United Kingdom in 2009 with another office in North America. They experienced that their customers almost never exploit unstructured company data (like metadata) and in the best case only half of the structured data (like JSON files, or syslogs …) in their Big Data solution.
They concluded the two main Big Data challenges are:
1 – How to process and analyze all of those unexploited data to create value
2 – How to make them available to data scientists while keeping them private from the rest of the company as currently, usually, around 70% of company employees have access to data they’re not supposed to…
Initially, Big Data technology was mainly challenged by what is called the 3V or how to deal with the Volume of data, the Velocity, how fast it appears, as well as the Variety. Today, especially with the Public Cloud, those aspects are mostly addressed by the available technologies and tools but arrived the two new challenges of making something useful of those data as well as making them available to data scientists, as represented on the following slide.
To conceive this Big Data Analysis platform (ed In the Public Cloud) and allow it to scale, here are the six strategic principles of Data Management:
- Use available PaaS and SaaS services as much as possible,
- Automatize as much as possible calculation and data/process cleaning,
- Secure data: logically, physically, humanly,
- Make the different processes modular from input data to output results,
- Make it scalable (which solves most of the Big Data 3V challenges),
- Don’t overlook service Governance: human process and resources management. This last principle is the key to succeed at the five previous ones.
On a more operational aspect, there are a few things to keep in mind: data should be kept raw and analytic/visualisation should be in self-service.
On the Governance aspect, you should make sure to make data available only to the authorized user, manage the quality of service and data lifecycle (it doesn’t make sense).
Finally, few principles should be applied for metadata processing:
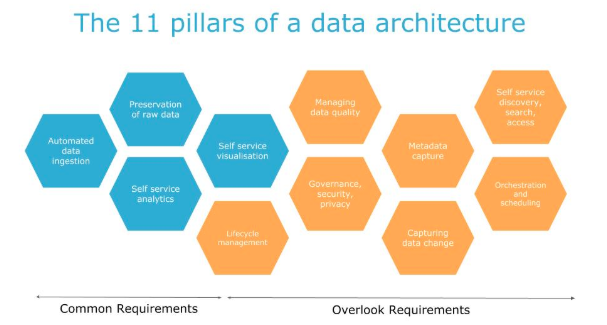
The four most common mistakes patterns they often find among their customers are:
- The overlook of data discovery, access management, and data/process cleaning after processing,
- They don’t want to deploy a Big Data solution before having a well-established production environment with enough viable data. Though, in reality, it’s much simpler to begin this kind of solution with a small sample of data to train teams with the processes and tools and to adopt scalability methods from the beginning,
- Clients migrate their Dataware in the Cloud without considering PaaS and SaaS services which could improve both scalability and cost of their solution,
- Once the platform is built, they overlook data discovery and governance aspects which have to be developed in the long-term.
See below the full vision from CloudReach engineers about what should be a Big Data analytic platform in AWS:
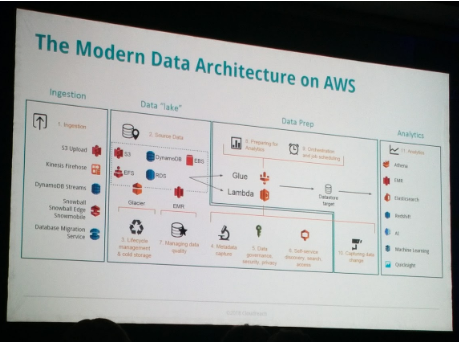
After Cloudreach’s theoric vision, let’s see how this kind of solution may be exploited concretely with the return of Experience from Euronext:
Euronext is a European Stock Exchange presents in 5 countries. Since their separation from the New York Stock Exchange in 2014, their capitalization has been multiplied by 3, from 14 to 60 euros per share. Since end 2015, they started a three years strategy business plan called “Agility for Growth”, which favors a DevOps and Cloud first approach to renew and improve the company services portfolio.
One of their primary focus was to leverage their Big Data analytic solution (BDM) with AWS Public Cloud and a new service Governance strategy. They reviewed what data they could make available, how it could be processed and what value they could get from it.
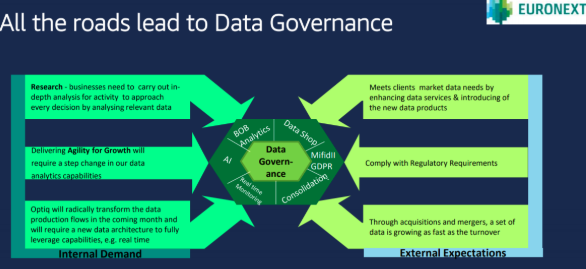
Furthermore, they needed to be able to get some data in near real-time and decided to leverage AWS data streaming services to reach this goal. The new legal framework such as MiFID II or the more global GDPR led them to increase their reporting needs as well as their needs for well structured Data Governance process.
To reach those goals, they migrated their DataLake from their legacy data centers to S3 to allow a faster data processing and enrichment with external feeds such as Reuters and Bloomberg thanks to AWS services.
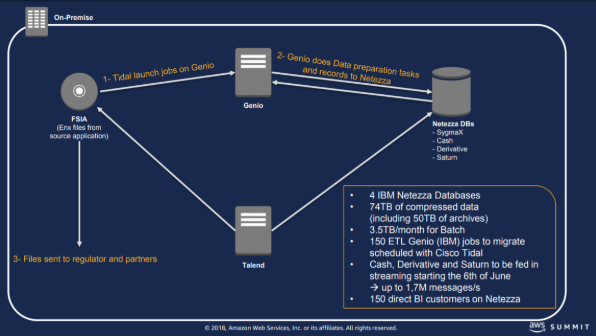
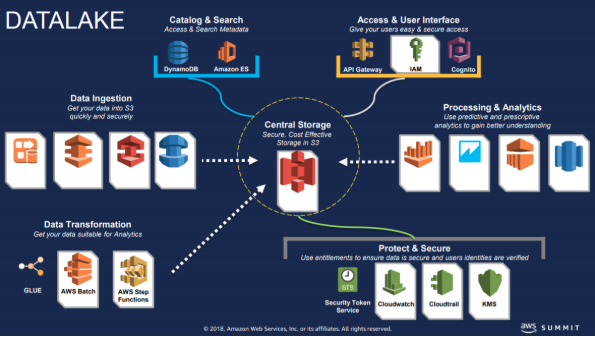 According to Paul de Monchy, senior consultant at AWS, the target to migrate the DataLake to S3 (ed a virtually infinite data store service), was to make of Euronext, a DataCentric company. While some of the data administration tools remained on-premise, one of the significant challenges for Euronext was to process the Data in the Cloud while leveraging AWS serverless and optimized costs capabilities.
According to Paul de Monchy, senior consultant at AWS, the target to migrate the DataLake to S3 (ed a virtually infinite data store service), was to make of Euronext, a DataCentric company. While some of the data administration tools remained on-premise, one of the significant challenges for Euronext was to process the Data in the Cloud while leveraging AWS serverless and optimized costs capabilities.
To reach this goal, multiple AWS services were combined to get a very atomic solution based on AWS Batch, ECR (an AWS managed container registry solution) and Spot Instances. To resume shortly how it works, when a new file is sent to S3 DataLake, an AWS event happens which triggers the AWS Batch job service. This job uses ECR and Spot instances to run a container which parallelized compute process at a reduced cost.
Note: A spot instance is an unused VM in AWS DataCenter. As they’re unused, users can bid a price up to 90% cheaper than the usual one to use the instance. The inconvenient of Spot instances is that if the demand increases and another user bids a higher price, the instance is immediately shut down without any warning. This specificity implies that Spot instances are usually not fit for constant workloads but well qualified for a punctual task such as an AWS batch job.
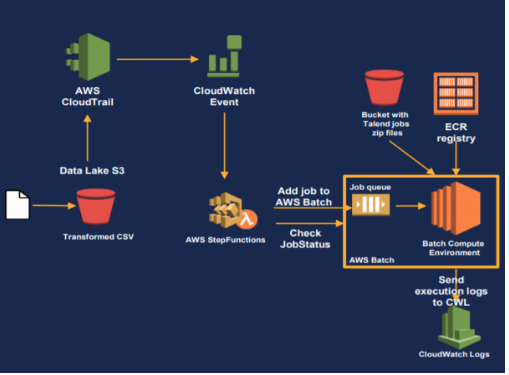
The final solution adopted by Euronext is fully serverless or using ephemeral resources such as Spot instances, which allowed them a consequent gain in the agility and scalability of their Big Data solution and associated processes as well as significant cost savings. It provides them far more time and resources they can dedicate to the enhancement of their solution and related services.
Most of the solution is open-sourced and available on Paul GitHub account: https://github.com/lePaulo/AWSDatalakeDataTransformationOrchestration

