By Mark Edmondson, Principal Data Engineer, Devoteam.
This article was initially published on Mark Edmondson’s personal and professional blog, available at: https://code.markedmondson.me/ and the following blog post constitutes a representation of the content of the original article.
As old readers may remember, I’ve always tried to work on the meta-horizons of where I am, restlessly looking for the next exciting lesson, and that impulse has led me to Large Language Models (LLMs) sparked off by the Chat-GPT revolution, but foreshadowed by the image generation models such as Stable Diffusion a few months before.
A key facilitator has been Harrison Chase’s Langchain, an active hive of open-source goodness. It has allowed me to learn and imagine and digest this new active field of LLMops (Large Language Model Operations), that is the data engineering to make LLMs actually useful on a day to day basis. I took it upon myself to see how I could apply my Google Cloud Platform (GCP) data engineering background to these new toys Langchain has helped provide.
This means I now have this new brain, Edmonbrain, that I converse with daily in Google Chat, Slack and Discord. I have fed it in interesting URLs, Git repos and Whitepapers so I can build up a unique bot of my very own. I fed it my own book, and can ask it questions about it, for example:
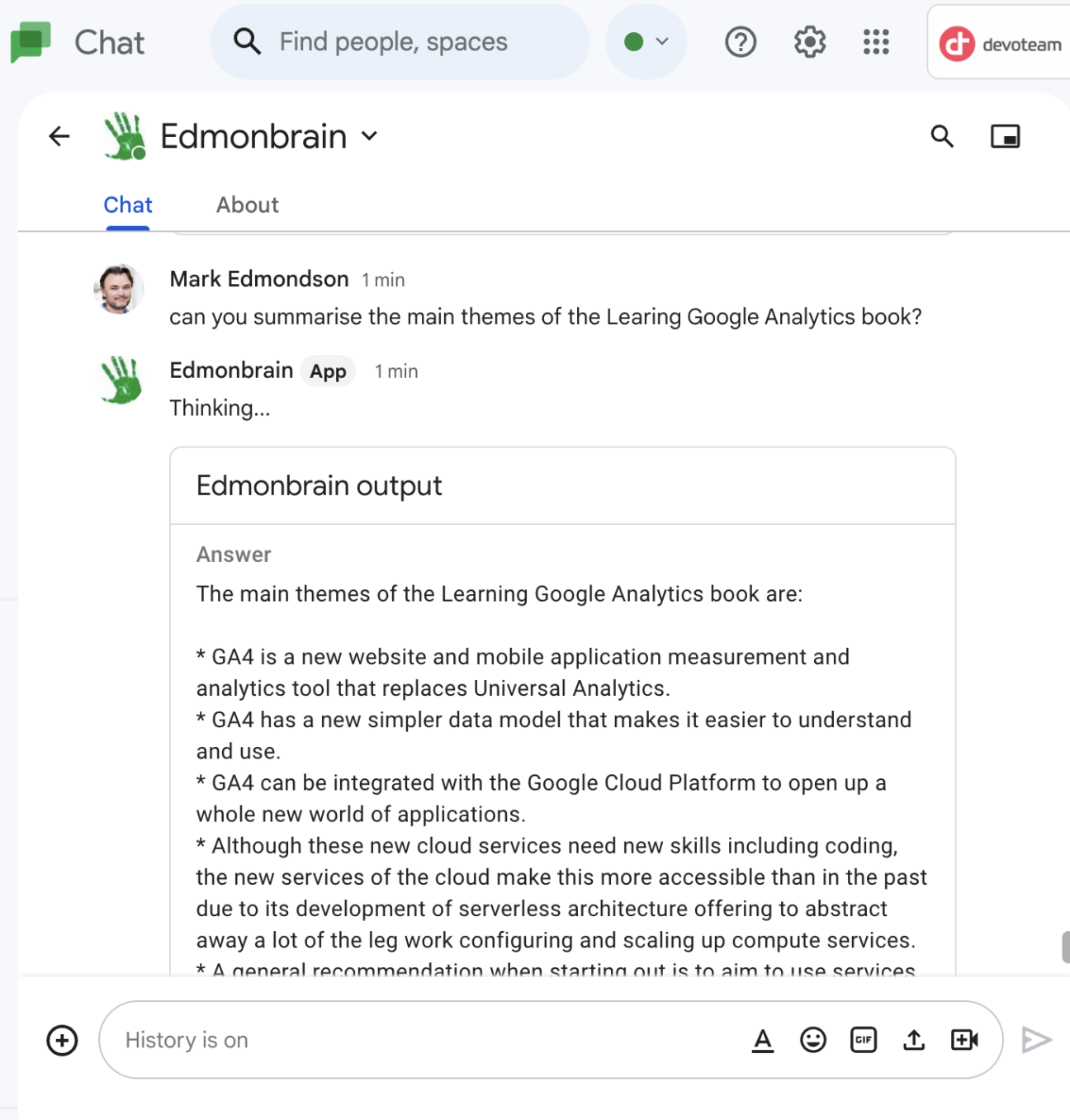
And I’m just getting started – imagine if we all shared a custom resource, and our feedback, questions and dreams are part of the bot’s context?
If you buy me a drink I will talk at length about how OpenAI, Google, Meta and Microsoft are interacting within this space, what the future may hold and what we can do already, but to keep a tight scope for this blog post I will share how I’ve made Edmonbrain: a chat-bot powered by LLMs that can talk about my own private data. As to the rest of the conversation about LLMs, I will for now only say I think I’m 20-50% more productive in developing ideas thanks to them, and that I do believe we are at a place where the nature of work will change as a result once that is applied more generally throughout the population. Naturally, Edmonbrain was very much LLM assisted and it was amazing to work with.
My Aims for LLMOps on Google Cloud Platform
My general aims for this data architecture were the following:
- As cheap as possible – scale-to-zero serverless
- As modular as possible – ability to switch out between models, databases and UIs
- Extendable – Be able to add new endpoints easily
- Private – be able to involve no 3rd parties outside of GCP, my trusted cloud provider
- Scalable – be able to go from zero to a billion if I pay money
- Easy to add your own data to – I wanted users to easily add their own sources such as URLs, GitHub repos, Google Drive folders etc.
- No authentication keys – use Google metadata to auth for ease of use and security
My primary aim was to have a way for an entire company to share all their emails, internal documents, chats, documentation and have an LLM bot that could reply to questions against those documents to anyone who asked. A “company wide brain”. My ambition is that if adopted it could enable more efficient communication between colleagues in a familiar context, using the chat apps they already use.
On GCP the above requirements always meant to me I would be running Cloud Run and Pub/Sub within my main orchestration. Once Google announced support for pgvector on AlloyDB and CloudSQL, this also meant I had more options other than the enterprise Matching Engine for a vectorstore to keep it all pure-GCP. But I’m getting ahead of myself, lets show some of the main features that LLMOps as a field is creating as an emerging standard.
What is needed for running an LLM bot?
- Large Language Model (LLM) – the “brain” that will respond to the text you send in. This is the magic that enables everything else. It supplies the intrinsic language understanding that was lacking in previous bots, and advanced LLMs can be like conversing to a knowledgeable individual
- Chat history – to make conversations natural, the LLM needs a short-term memory on what has happened. This doesn’t come for free (yet) in the APIs. You need to supply the chat history and add it to the API calls you are making to the LLM
- Context – this is the current piece that is enabling a lot of excitement at the moment. It basically means you pasting in a few examples or text context to any question you are asking, to help facilitate the LLMs answer, a form of prompt engineering. If you ask “What is my name?” tools such as Langchain can turn that prompt into “Answer below based on the context provided: What is my name? Context: Mark Edmondson is the creator of this tool”. Its a simple idea but with very powerful applications once you automate generating that context.
- Vectorstore – this is the hot new tech that enables the context above. You have a limited window of text to add to prompts, although there is a new arms race about which model can provide the largest context window (1 billion tokens?). Vectorstores hold the vectors of text embeddings that help similarity searches so you can select the best context to add to the prompt to help its answers. The gif below from Matching Engine helps illustrate what they are doing: vectors are similar if encoding similar context, and so you look for points close to existing embedded vectors when you get a new prompt so that the context returned is hopefully useful.
The first material I produced for LLM on GCP was this slide deck on “Edmonbrain – building a brain” in June 2023. I have to mention the date, as its probably already out of date given the pace of updates at the moment. It includes introducing a few key components that I summarise below:

- UX – how you interact with the bot. Although there are lots of web based chat bots out there, I avoided the rabbit hole of building a UI by favouring building LLM powered bots in the chat platforms I use daily, namely Discord, Slack and Google Chat. You get a lot of features for free such as chat history, user management and mobile/desktop apps.
- Orchestration – you need something that strings all the above components together. Langchain excels here since it offers a consistent API where you can swap out betwen say the OpenAI and VertexAI LLM models, or a different vectorstore such as Supabase, Chroma or CloudSQL.
The above are represented by these data architecture diagrams that I’ve made or saved from the web. Incidentally, @Langchain is also a great social media account to follow to keep up to date with all of the above, and was how I found out about these concepts.
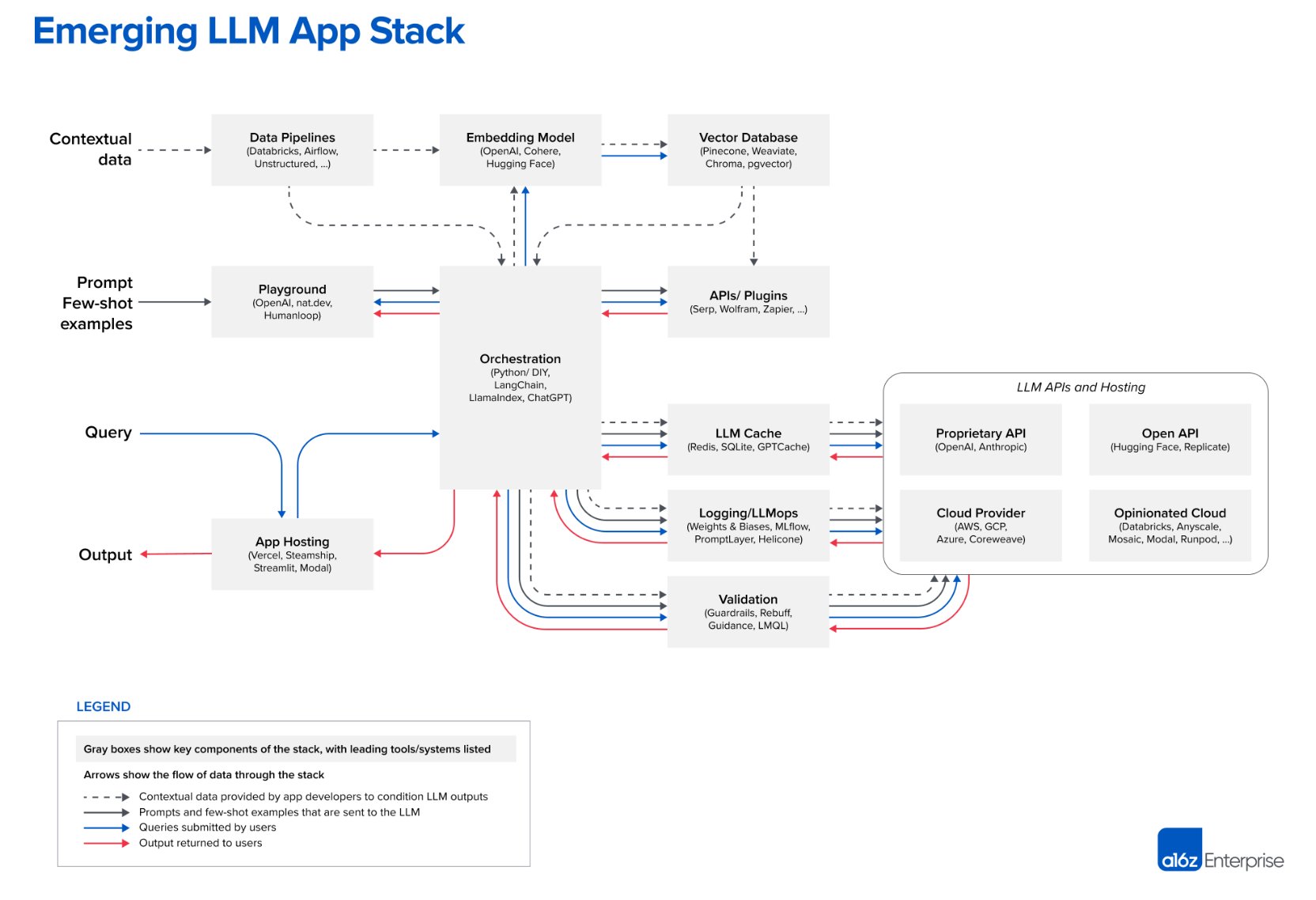
The diagram above is from a comprehensive post called Emerging Architectures for LLM Applications by a16z.com which was my first realisation this LLMOps is an emerging field that I’d like to be involved with.
Below is a diagram I made that helped me break down what I needed for my project:
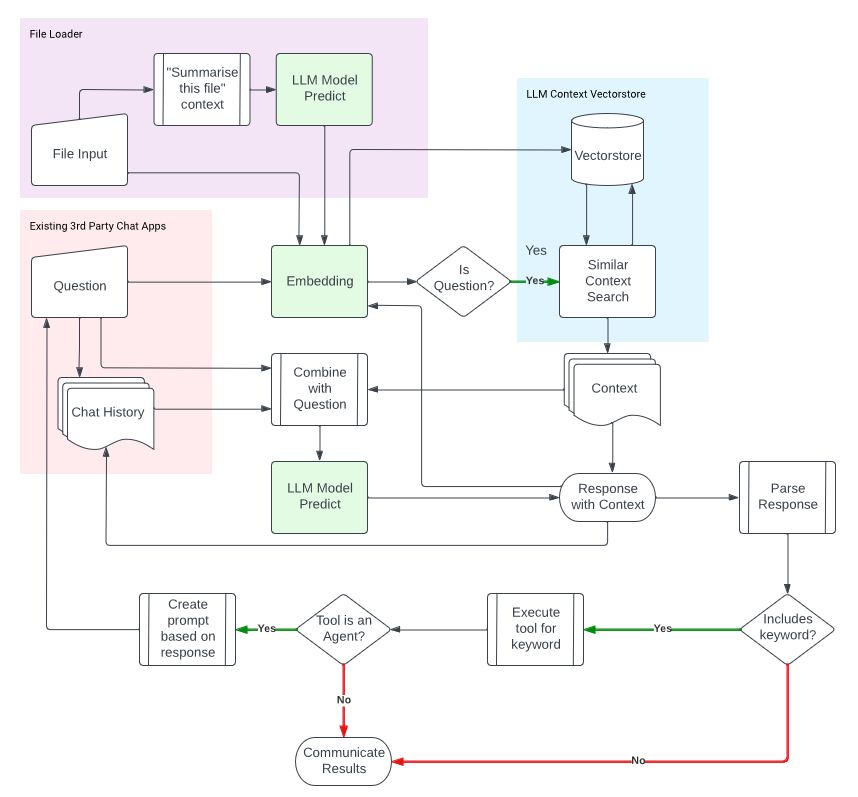
What I don’t cover in this blog are the tools or agents at the bottom. Thats my next step. But this diagram was the blueprint to what I built below.
Google Cloud Platform’s Data Architecture for LLMOps
My solution was to use Cloud Run running various HTTP apps that are used as micro-services for all the different components. This allowed me to tailor code for each micro-service as necessary, and to also take advantage of serverless scale to make big parallel processing when needed, but scale to zero when quiet. The Cloud Run services include:
- Google Chat App – this accepts HTTP requests from a Google Chat bot, parses the questions into suitable format for the QA service. It also includes some slash command processing to change behaviour such as a different LLM (Codey vs Bison). It receives the answers back from the QA service, and sends them with formatting back to the user.
- Slack and Discord – similarly, there are Slack and Discord Apps dealing with their own APIs but outputting the same as the Google Chat App to the QA service.
- Question/Answer (QA) App – this accepts questions and chat history and sends them to the LLM for answering. It runs Langchain to enable the various cool applications it has, such as ConversationalRetrievalChain, which call the vectorstore for context before sending to the LLM.
- Embedding service – when a user issues a command (!saveurl ) or when it receives a PubSub message from a file broadcast from the attached Cloud Storage bucket, this service receives the raw file and sends it to the Unstructured service. That Unstructured service creates Langchain Documents() that can then be chunked and passed into embedding. The number of chunks per document can get large (1000s for a large PDF), so each chunk is sent separately in its own PubSub message, which scales up the Cloud Run app to support demand and scales back to 0. This speeds up embedding A LOT. I also added some special parses to improve usability, so for example if the URL starts with https://github.com then it will attempt to clone that repo and embed every file within it, or if it starts with https://drive.google.com then it will direct the load from the Google Drive loaders.
- Unstructured service – you can call the Unstructured API with an API key if you want, but to keep documents private and within GCP you can host your own Unstructured easily using their pre-made Docker container. This accepts Document parsing requests from the Embedding service
- CloudSQL – the only non-serverless bit is CloudSQL running PostgreSQL to use the pgvector extension. (video about this here) This is the database that can connect to Cloud Run via a Private VPC so no need for a public IP. I’m wondering when/if this should be switched out for AlloyDB (which has some built in ML features) or Matching Engine (which has enterprise pricing, but may perform better for 10k + documents)
- Cloud Storage – this is another way to load the Embedding service, since you can link a PubSub message to the Cloud Run endpoint. This is handy for lots of documents added at once, or you have existing data flows putting documents into Cloud Storage.
- Pub/Sub – this is the glue that binds the Apps together, and allows you to message queue big chunky embeddings and/or send data to different destinations. For example, each question/answer thread may themselves hold valuable training data, so those answers are also piped to BigQuery for use later on.
Here is how it fits together, including the optional 3rd party options outside of GCP.
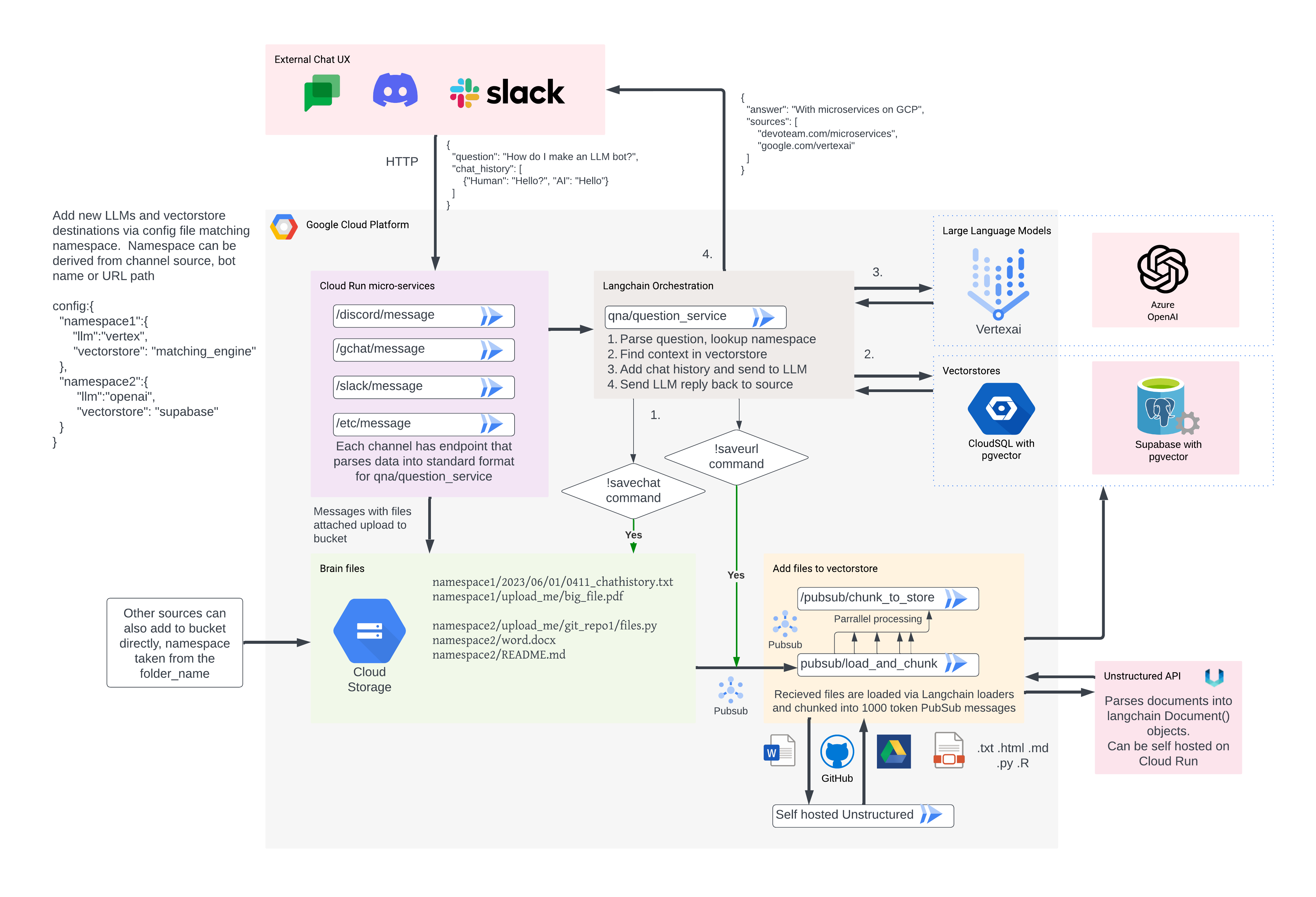
The diagram covers the various services that GCP provide – Cloud Run is represented a lot and each Cloud Run box is its own micro-service, connected via PubSub and/or HTTP.
Code examples for the LLM Cloud Run services
Just to give you a flavour of the code required, here are some examples from various app services. If you want to browse at depth my working Edmonbrain back-end on GCP, the code is open-sourced here: https://github.com/MarkEdmondson1234/edmonbrain or see the development leading up to it at this playground: https://github.com/MarkEdmondson1234/langchain-github.
Google Chat
The Google Chat service uses PubSub since you must reply within 30secs so the Q&A service needed to be asynchronous in case it was longer than that (its usually under 10 seconds to generate a response but longer more complicated answers could happen).

I generated Google Chat Card for output as it looked nice, although not for Codey that will only output text since its output includes back tick code blocks that didn’t work with Card format. Authentication is done using Cloud Run’s default service account, but for downloading chat history it seems this is only available with explicit opt-in by the user.
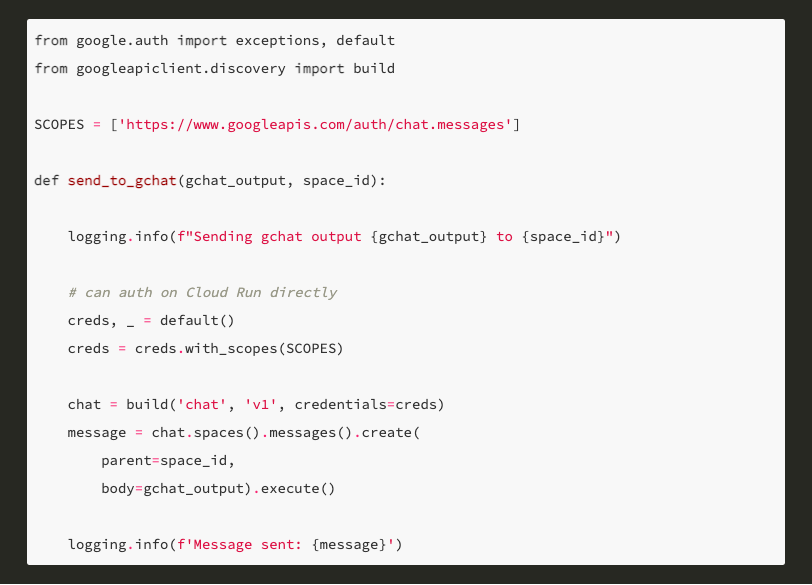
Discord’s API was easier to work with to get chat history and message events, and was my favourite compared to Slack and Google Chat.
CloudSQL running PostgreSQL with pgvector
Langchain already has an existing PGVector connector which I reused for CloudSQL. I can see a business in embedding documents with a certain embedding size and selling those pre-done.
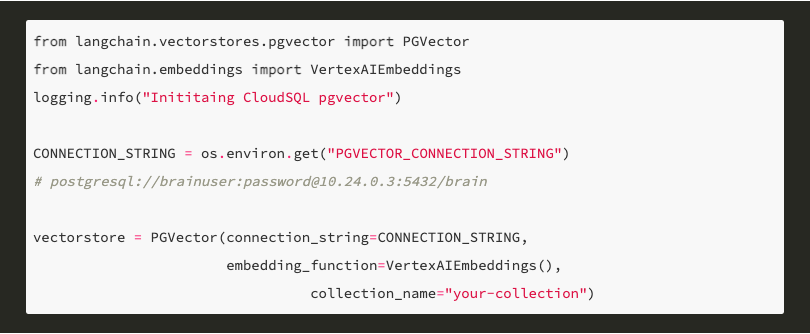
Setting up the CloudSQL instance was simple enough. I opted for a private IP instance and used a serverless VPC connector as described at these links:
- https://cloud.google.com/sql/docs/postgres/connect-run#private-ip_1
- https://cloud.google.com/sql/docs/postgres/connect-instance-cloud-run
I then needed to specify the VPC connector when creating the Cloud Run service within Cloud Run via the –vpc-connector flag and the database was found at the private ip (10.24.0.3 in above code snippet). I then constructed the PGVECTOR_CONNECTION_STRING and placed it in Secret Manager, accessible during Cloud Run start up via:
–update-secrets=PGVECTOR_CONNECTION_STRING=PGVECTOR_CONNECTION_STRING:latest
Hosting Unstructured Document Loading on Cloud Run
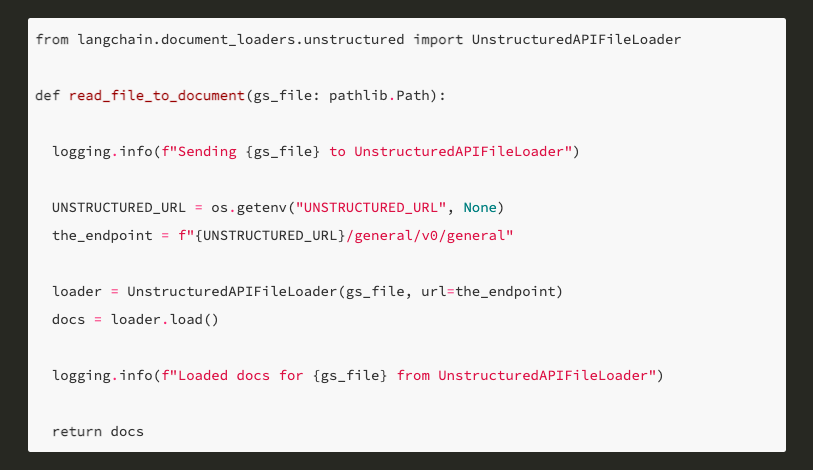
Unstructured is a great short cut to parsing out lots of different file formats that can work with embeddings. The easiest way to get started is to just call their API with your files for which you need a free API key, but for private documents I hosted my own instance on a bigger Cloud Run instance since parsing PDFs can get pretty intensive CPU wise as it uses OCR techniques to read diagrams etc.
Once a Cloud Run URL was available then it was just a matter of pointing the function at your own URL endpoint rather than the public one:
Q&A Service
The LLM API calls along with additional context from your documents is handled by Langchain, featured on TechRadar by Devoteam. The choice of which vector store or LLM is made by a simple config file that looks at the name space. For example, Edmonbrain running in Discord uses Supabase/OpenAI whilst GoogleBrain on GChat uses Vertex and CloudSQL. Langchain’s abstractions means you can run the same chat operation across both:

I also plan to be able to customise the prompt more, since this is an area where a lot of optimisation can happen. Eventually I also want to enable Agents, that trigger actions via code functions you ask the LLM to create variables for, and feed it back the results. This is an exciting rapidly developing field.
Summary
I’m aware that a lot of the infrastructure I’ve built may be made redundant as Google and other companies launch their own GenAI products. I got a demo of Google’s GenApp builder and looks like you can set up your own chat bot over your own documents with a few clicks, and get some JavaScript to embed that app anyway you like.
However, its been so educational for me to work through the infrastructure and I’m sure for custom solutions going forward it will stand me in good stead. I may be able to swap in and out easily with my modular structure some GenApp builder elements, but keep my own custom prompts, for example. All in all its a good basis for the next stage, which I believe will be the how unsupervised LLMs interacting by themselves will behave. Will we ever be able to eliminate hallucinations to make them reliable enough to not need human interaction? Is code syntax doomed, and we will be able to program solely via concepts?
I do feel changed by having LLM assistance in this project and will not be able to go back to having none. It’s like an enthusiastic intern coding buddy that can quickly return research results. I look back at my time without LLM assistance and wonder at how much time was spent just struggling with syntax instead of advancing or trying out ideas. All in all its an exciting time to be working within data, and I look forward to seeing what develops. Please get in touch if you wish to feedback, speculate or build something related to it, as I think its going to be a big part of our future.
Meet Devoteam at Computerworld Cloud Festival
Want to meet Mark Edmondsen in person? Sign up for Computerworld Cloud Festival September 20 – 21, where you can meet Mark at our booth, sharing an exciting TechTalk.

